
Here’s a popular story about momentum
This standard story isn’t wrong, but it fails to explain many important behaviors of momentum. In fact, momentum can be understood far more precisely if we study it on the right model.
One nice model is the convex quadratic. This model is rich enough to reproduce momentum’s local dynamics in real problems, and yet simple enough to be understood in closed form. This balance gives us powerful traction for understanding this algorithm.
We begin with gradient descent. The algorithm has many virtues, but speed is not one of them. It is simple — when optimizing a smooth function f
wk+1=wk−α∇f(wk).
For a step-size small enough, gradient descent makes a monotonic improvement at every iteration. It always converges, albeit to a local minimum. And under a few weak curvature conditions it can even get there at an exponential rate.
But the exponential decrease, though appealing in theory, can often be infuriatingly small. Things often begin quite well — with an impressive, almost immediate decrease in the loss. But as the iterations progress, things start to slow down. You start to get a nagging feeling you’re not making as much progress as you should be. What has gone wrong?
The problem could be the optimizer’s old nemesis, pathological curvature. Pathological curvature is, simply put, regions of f
Momentum proposes the following tweak to gradient descent. We give gradient descent a short-term memory:
zk+1wk+1=βzk+∇f(wk)=wk−αzk+1
The change is innocent, and costs almost nothing. When β=0 β=0.99 0.999
Optimizers call this minor miracle “acceleration”.
The new algorithm may seem at first glance like a cheap hack. A simple trick to get around gradient descent’s more aberrant behavior — a smoother for oscillations between steep canyons. But the truth, if anything, is the other way round. It is gradient descent which is the hack. First, momentum gives up to a quadratic speedup on many functions.
But there’s more. A lower bound, courtesy of Nesterov
First Steps: Gradient Descent
We begin by studying gradient descent on the simplest model possible which isn’t trivial — the convex quadratic,
f(w)=21wTAw−bTw,w∈Rn.
Assume A w⋆
w⋆=A−1b.
Simple as this model may be, it is rich enough to approximate many functions (think of A
This is how it goes. Since ∇f(w)=Aw−b
wk+1=wk−α(Awk−b).
Here’s the trick. There is a very natural space to view gradient descent where all the dimensions act independently — the eigenvectors of A
Every symmetric matrix A
A=Q diag(λ1,…,λn) QT,Q=[q1,…,qn],
and, as per convention, we will assume that the λi λ1 λn xk=QT(wk−w⋆)
xik+1=xik−αλixik=(1−αλi)xik=(1−αλi)k+1xi0
Moving back to our original space w
wk−w⋆=Qxk=i∑nxi0(1−αλi)kqi
and there we have it — gradient descent in closed form.
Decomposing the Error
The above equation admits a simple interpretation. Each element of x0 Q n 1−αλi 1
For most step-sizes, the eigenvectors with largest eigenvalues converge the fastest. This triggers an explosion of progress in the first few iterations, before things slow down as the smaller eigenvectors’ struggles are revealed. By writing the contributions of each eigenspace’s error to the loss f(wk)−f(w⋆)=∑(1−αλi)2kλi[xi0]2
λ1=0.01
λ2=0.1
λ3=1
Step-size
Optimal Step-size
Choosing A Step-size
The above analysis gives us immediate guidance as to how to set a step-size α ∣1−αλi∣
0<αλi<2.
The overall convergence rate is determined by the slowest error component, which must be either λ1 λn rate(α) = imax∣1−αλi∣ = max{∣1−αλ1∣, ∣1−αλn∣}
This overall rate is minimized when the rates for λ1 λn
optimal α = αargmin rate(α)optimal rate = αmin rate(α) = λ1+λn2 = λn/λ1+1λn/λ1−1
Notice the ratio λn/λ1 condition number:=κ:=λ1λn A−1b b κ=1
Example: Polynomial Regression
The above analysis reveals an insight: all errors are not made equal. Indeed, there are different kinds of errors, n A A
Lets see how this plays out in polynomial regression. Given 1D data, ξi
model(ξ)=w1p1(ξ)+⋯+wnpn(ξ)pi=ξ↦ξi−1
to our observations, di ξ
Because of the linearity, we can fit this model to our data ξi
minimizew21i∑(model(ξi)−di)2 = 21∥Zw−d∥2
Z=⎝⎜⎜⎛11⋮1ξ1ξ2⋮ξmξ12ξ22⋮ξm2……⋱…ξ1n−1ξ2n−1⋮ξmn−1⎠⎟⎟⎞.
The path of convergence, as we know, is elucidated when we view the iterates in the space of Q ZTZ Q w Qw p p¯
model(ξ) = x1p¯1(ξ) + ⋯ + xnp¯n(ξ)p¯i=∑qijpj.
This model is identical to the old one. But these new features p¯ n
The observations in the above diagram can be justified mathematically. From a statistical point of view, we would like a model which is, in some sense, robust to noise. Our model cannot possibly be meaningful if the slightest perturbation to the observations changes the entire model dramatically. And the eigenfeatures, the principal components of the data, give us exactly the decomposition we need to sort the features by its sensitivity to perturbations in di
This measure of robustness, by a rather convenient coincidence, is also a measure of how easily an eigenspace converges. And thus, the “pathological directions” — the eigenspaces which converge the slowest — are also those which are most sensitive to noise! So starting at a simple initial point like 0
This effect is harnessed with the heuristic of early stopping : by stopping the optimization early, you can often get better generalizing results. Indeed, the effect of early stopping is very similar to that of more conventional methods of regularization, such as Tikhonov Regression. Both methods try to suppress the components of the smallest eigenvalues directly, though they employ different methods of spectral decay.
The Dynamics of Momentum
Let’s turn our attention back to momentum. Recall that the momentum update is
zk+1wk+1=βzk+∇f(wk)=wk−αzk+1.
Since ∇f(wk)=Awk−b
zk+1wk+1=βzk+(Awk−b)=wk−αzk+1.
Following xk=Q(wk−w⋆) yk=Qzk
yik+1xik+1=βyik+λixik=xik−αyik+1.
in which each component acts independently of the other components (though xik yik
(yikxik)=Rk(yi0xi0)R=(β−αβλi1−αλi).
kth
2×2
R
σ1
σ2
Rk={σ1kR1−σ2kR2σ1k(kR/σ1−(k−1)I)σ1≠σ2σ1=σ2,Rj=σ1−σ2R−σjI
This formula is rather complicated, but the takeaway here is that it plays the exact same role the individual convergence rates, 1−αλi max{∣σ1∣,∣σ2∣}
Convergence Rate
max{∣σ1∣,∣σ2∣}
For what values of α β σ1 σ2 max{∣σ1∣,∣σ2∣}<1
0<αλi<2+2βfor0≤β<1
We recover the previous result for gradient descent when β=0
The Critical Damping Coefficient
The true magic happens, however, when we find the sweet spot of α β β
Momentum admits an interesting physical interpretation when α
yik+1
=
+
λixik −yik βyik xik+1
=
xik−αyik+1 x yik+1
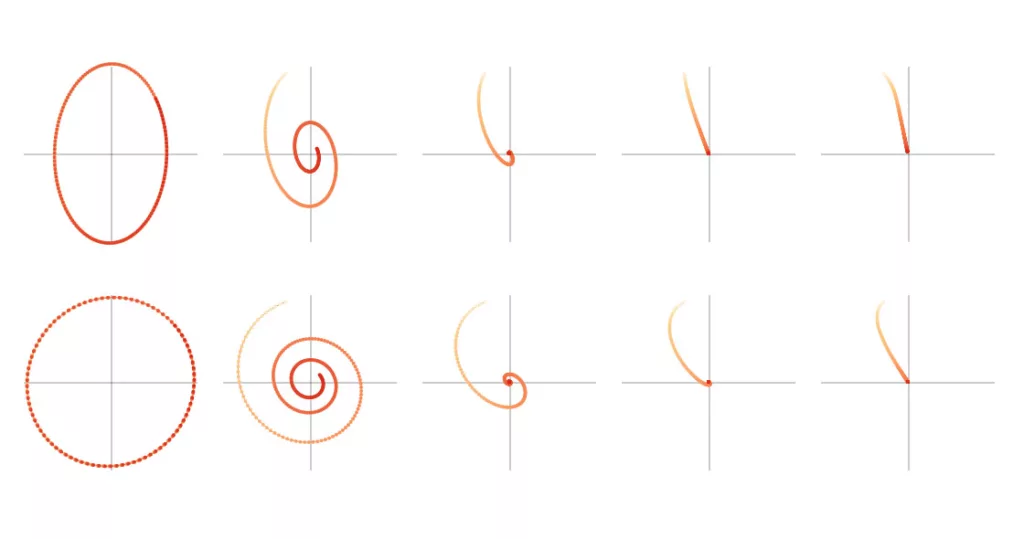
We can break this equation apart to see how each component affects the dynamics of the system. Here we plot, for 150
This system is best imagined as a weight suspended on a spring. We pull the weight down by one unit, and we study the path it follows as it returns to equilibrium. In the analogy, the spring is the source of our external force λixik xik yik β
The critical value of β=(1−√αλi)2 i 1−√αλi. 1−αλi ith α
Optimal parameters
To get a global convergence rate, we must optimize over both α β α=(√λ1+√λn2)2β=(√λn+√λ1√λn−√λ1)2
√κ+1√κ−1 κ+1κ−1
With barely a modicum of extra effort, we have essentially square rooted the condition number! These gains, in principle, require explicit knowledge of λ1 λn α 1 β 1 α
λ1=0.01
λ2=0.1
λ3=1
f(wk)−f(w⋆)
Step-size α =
Momentum β =
While the loss function of gradient descent had a graceful, monotonic curve, optimization with momentum displays clear oscillations. These ripples are not restricted to quadratics, and occur in all kinds of functions in practice. They are not cause for alarm, but are an indication that extra tuning of the hyperparameters is required.
Example: The Colorization Problem
Let’s look at how momentum accelerates convergence with a concrete example. On a grid of pixels let G E D
minimize
21i∈D∑(wi−1)2 +
21i,j∈E∑(wi−wj)2.
The optimal solution to this problem is a vector of all 1
wik+1=wik−αj∈N∑(wik−wjk)−{α(wik−1)0i∈Di∉D
This kind of local averaging is effective at smoothing out local variations in the pixels, but poor at taking advantage of global structure. The updates are akin to a drop of ink, diffusing through water. Movement towards equilibrium is made only through local corrections and so, left undisturbed, its march towards the solution is slow and laborious. Fortunately, momentum speeds things up significantly.
Rn
In vectorized form, the colorization problem is
minimize 21i∈D∑(xTeieiTx−eiTx)
+
21xTLGx ei ith
The Laplacian matrix, LG LG
These observations carry through to the colorization problem, and the intuition behind it should be clear. Well connected graphs allow rapid diffusion of information through the edges, while graphs with poor connectivity do not. And this principle, taken to the extreme, furnishes a class of functions so hard to optimize they reveal the limits of first order optimization.
The Limits of Descent
Let’s take a step back. We have, with a clever trick, improved the convergence of gradient descent by a quadratic factor with the introduction of a single auxiliary sequence. But is this the best we can do? Could we improve convergence even more with two sequences? Could one perhaps choose the α β
Unfortunately, while improvements to the momentum algorithm do exist, they all run into a certain, critical, almost inescapable lower bound.
Adventures in Algorithmic Space
To understand the limits of what we can do, we must first formally define the algorithmic space in which we are searching. Here’s one possible definition. The observation we will make is that both gradient descent and momentum can be “unrolled”. Indeed, since w^{k+1} & != & !w^{0} ~-~ alphanabla f(w^{0}) ~-~~~~ cdotscdots ~~~~-~ alphanabla f(w^{k})
end{array}
w1w2wk+1=== ⋮=w0 − α∇f(w0)w1 − α∇f(w1)w0 − α∇f(w0) − α∇f(w1)w0 − α∇f(w0) − ⋯⋯ − α∇f(wk)
wk+1 = w0 − αi∑k∇f(wi).
A similar trick can be done with momentum:
wk+1 = w0 + αi∑k1−β(1−βk+1−i)∇f(wi).
In fact, all manner of first order algorithms, including the Conjugate Gradient algorithm, AdaMax, Averaged Gradient and more, can be written (though not quite so neatly) in this unrolled form. Therefore the class of algorithms for which
wk+1 = w0 + i∑kγik∇f(wi) for some γik
contains momentum, gradient descent and a whole bunch of other algorithms you might dream up. This is what is assumed in Assumption 2.1.4
wk+1 = w0 + i∑kΓik∇f(wi) for some diagonal matrix Γik.
This class of methods covers most of the popular algorithms for training neural networks, including ADAM and AdaGrad. We shall refer to this class of methods as “Linear First Order Methods”, and we will show a single function all these methods ultimately fail on.
The Resisting Oracle
Earlier, when we talked about the colorizer problem, we observed that wiry graphs cause bad conditioning in our optimization problem. Taking this to its extreme, we can look at a graph consisting of a single path — a function so badly conditioned that Nesterov called a variant of it “the worst function in the world”. The function follows the same structure as the colorizer problem, and we shall call this the Convex Rosenbrock,
fn(w)
= 21(w1−1)2
+
21i=1∑n(wi−wi+1)2 + κ−12∥w∥2.
The optimal solution of this problem is
wi⋆=(√κ+1√κ−1)i
and the condition number of the problem fn κ n w0=0
Step-size α =
Momentum β =
n=25
Error
Weights
The observations made in the above diagram are true for any Linear First Order algorithm. Let us prove this. First observe that each component of the gradient depends only on the values directly before and after it:
∇f(x)i=2wi−wi−1−wi+1+κ−14wi,i≠1.
Therefore the fact we start at 0 guarantees that that component must remain stoically there till an element either before or after it turns nonzero. And therefore, by induction, for any linear first order algorithm,
w0w1w2wk=== ⋮=[ 0,[ w11,[ w12,[ w1k,0,0,w22,w2k,0,0,0,w3k,…………0,0,0,wkk,0,0,0,0,…………0 ]0 ]0 ]0 ].
Think of this restriction as a “speed of light” of information transfer. Error signals will take at least k w0 wk
∥wk−w⋆∥∞≥i≥k+1max{∣wi⋆∣}=(√κ+1√κ−1)k+1=(√κ+1√κ−1)k∥w0−w⋆∥∞.
As n fn κ
Like many such lower bounds, this result must not be taken literally, but spiritually. It, perhaps, gives a sense of closure and finality to our investigation. But this is not the final word on first order optimization. This lower bound does not preclude the possibility, for example, of reformulating the problem to change the condition number itself! There is still much room for speedups, if you understand the right places to look.
Momentum with Stochastic Gradients
There is a final point worth addressing. All the discussion above assumes access to the true gradient — a luxury seldom afforded in modern machine learning. Computing the exact gradient requires a full pass over all the data, the cost of which can be prohibitively expensive. Instead, randomized approximations of the gradient, like minibatch sampling, are often used as a plug-in replacement of ∇f(w)
∇f(w) +
error(w). E[error(w)]=0
If the estimator is unbiased e.g.
It is helpful to think of our approximate gradient as the injection of a special kind of noise into our iteration. And using the machinery developed in the previous sections, we can deal with this extra term directly. On a quadratic, the error term cleaves cleanly into a separate term, where
(yikxik) =
Rk(yi0xi0) +
ϵikj=1∑kRk−j(1−α) ϵk=Q⋅error(wk)
The error term, ϵk wk
Ef(w)−f(w⋆)
Ef(w)−f(w⋆)
Step-size α =
Momentum β =
Note that there are a set of unfortunate tradeoffs which seem to pit the two components of error against each other. Lowering the step-size, for example, decreases the stochastic error, but also slows down the rate of convergence. And increasing momentum, contrary to popular belief, causes the errors to compound. Despite these undesirable properties, stochastic gradient descent with momentum has still been shown to have competitive performance on neural networks. As
Onwards and Downwards
The study of acceleration is seeing a small revival within the optimization community. If the ideas in this article excite you, you may wish to read
Acknowledgments
I am deeply indebted to the editorial contributions of Shan Carter and Chris Olah, without which this article would be greatly impoverished. Shan Carter provided complete redesigns of many of my original interactive widgets, a visual coherence for all the figures, and valuable optimizations to the page’s performance. Chris Olah provided impeccable editorial feedback at all levels of detail and abstraction – from the structure of the content, to the alignment of equations.
I am also grateful to Michael Nielsen for providing the title of this article, which really tied the article together. Marcos Ginestra provided editorial input for the earliest drafts of this article, and spiritual encouragement when I needed it the most. And my gratitude extends to my reviewers, Matt Hoffman and Anonymous Reviewer B for their astute observations and criticism. I would like to thank Reviewer B, in particular, for pointing out two non-trivial errors in the original manuscript (discussion here). The contour plotting library for the hero visualization is the joint work of Ben Frederickson, Jeff Heer and Mike Bostock.
Many thanks to the numerous pull requests and issues filed on github. Thanks in particular, to Osemwaro Pedro for spotting an off by one error in one of the equations. And also to Dan Schmidt who did an editing pass over the whole project, correcting numerous typographical and grammatical errors.
Discussion and Review
Reviewer A – Matt Hoffman
Reviewer B – Anonymous
Discussion with User derifatives
Footnotes
- It is possible, however, to construct very specific counterexamples where momentum does not converge, even on convex functions. See
[4] for a counterexample. - In Tikhonov Regression we add a quadratic penalty to the regression, minimizing
minimize21∥Zw−d∥2+2η∥w∥2=21wT(ZTZ+ηI)w−(Zd)Tw
ZTZ=Q diag(Λ1,…,Λn) QT
(ZTZ+ηI)−1(Zd)=Q diag(λ1+η1,⋯,λn+η1)QT(Zd)
Tikhonov Regularized λi=λi+η1=λi1(1−(1+λi/η)−1).
Gradient Descent Regularized λi=λi1(1−(1−αλi)k)
-
This is true as we can write updates in matrix form as
(1α01)(yik+1xik+1)=(β0λi1)(yikxik)
which implies, by inverting the matrix on the left,
(yik+1xik+1)=(β−αβλi1−αλi)(yikxik)=Rk+1(xi0yi0)
-
We can write out the convergence rates explicitly. The eigenvalues are
σ1σ2=21(1−αλ+β+√(−αλ+β+1)2−4β)=21(1−αλ+β−√(−αλ+β+1)2−4β)
(−αλ+β+1)2−4β<0
then the roots are complex and the convergence rate is∣σ1∣=∣σ2∣=√(1−αλ+β)2+∣(−αλ+β+1)2−4β∣=2√β
αλ
max{∣σ1∣,∣σ2∣}=21max{∣1−αλi+β±√(1−αλi+β)2−4β∣}
- This can be derived by reducing the inequalities for all 4 + 1 cases in the explicit form of the convergence rate above.
- We must optimize over
α,βminmax{∥∥∥∥(β−αβλi1−αλi)∥∥∥∥,…,∥∥∥∥(β−αβλn1−αλn)∥∥∥∥}.
∥⋅∥
- The above optimization problem is bounded from below by
0
1
- This can be written explicitly as
[LG]ij=⎩⎪⎨⎪⎧degree of vertex i−10i=ji≠j,(i,j) or (j,i)∈Eotherwise
- We use the infinity norm to measure our error, similar results can be derived for the 1 and 2 norms.
-
The momentum iterations are
zk+1wk+1=βzk+Awk+error(wk)=wk−αzk+1.
(1α01)(yik+1xik+1)=(β0λi1)(yikxik)+(ϵik0)
2×2
- On the 1D function
f(x)=2λx2
Ef(xk)=2λE[(xk)2]=2λE(e2TRk(y0x0)+ϵke2Ti=1∑kRk−i(1−α))2=2λe2TRk(y0x0)+2λE(ϵke2Ti=1∑kRk−i(1−α))2=2λe2TRk(y0x0)+2λE[ϵk]⋅i=1∑k(e2TRk−i(1−α))2=2λe2TRk(y0x0)+2λE[ϵk⋅i=1∑kγi2,γi=e2TRk−i(1−α)
Eϵk=0
References
- On the importance of initialization and momentum in deep learning. [PDF]
Sutskever, I., Martens, J., Dahl, G.E. and Hinton, G.E., 2013. ICML (3), Vol 28, pp. 1139—1147. - Some methods of speeding up the convergence of iteration methods [PDF]
Polyak, B.T., 1964. USSR Computational Mathematics and Mathematical Physics, Vol 4(5), pp. 1—17. Elsevier. DOI: 10.1016/0041-5553(64)90137-5 - Theory of gradient methods
Rutishauser, H., 1959. Refined iterative methods for computation of the solution and the eigenvalues of self-adjoint boundary value problems, pp. 24—49. Springer. DOI: 10.1007/978-3-0348-7224-9_2 - Analysis and design of optimization algorithms via integral quadratic constraints [PDF]
Lessard, L., Recht, B. and Packard, A., 2016. SIAM Journal on Optimization, Vol 26(1), pp. 57—95. SIAM. - Introductory lectures on convex optimization: A basic course
Nesterov, Y., 2013. , Vol 87. Springer Science & Business Media. DOI: 10.1007/978-1-4419-8853-9 - Natural gradient works efficiently in learning http://distill.pub/2017/momentum
Amari, S., 1998. Neural computation, Vol 10(2), pp. 251—276. MIT Press. DOI: 10.1162/089976698300017746 - Deep Learning, NIPS′2015 Tutorial [PDF]
Hinton, G., Bengio, Y. and LeCun, Y., 2015. - Adaptive restart for accelerated gradient schemes [PDF]
O’Donoghue, B. and Candes, E., 2015. Foundations of computational mathematics, Vol 15(3), pp. 715—732. Springer. DOI: 10.1007/s10208-013-9150-3 - The Nth Power of a 2×2 Matrix. [PDF]
Williams, K., 1992. Mathematics Magazine, Vol 65(5), pp. 336. MAA. DOI: 10.2307/2691246 - From Averaging to Acceleration, There is Only a Step-size. [PDF]
Flammarion, N. and Bach, F.R., 2015. COLT, pp. 658—695. - On the momentum term in gradient descent learning algorithms [PDF]
Qian, N., 1999. Neural networks, Vol 12(1), pp. 145—151. Elsevier. DOI: 10.1016/s0893-6080(98)00116-6 - Understanding deep learning requires rethinking generalization [PDF]
Zhang, C., Bengio, S., Hardt, M., Recht, B. and Vinyals, O., 2016. arXiv preprint arXiv:1611.03530. - A differential equation for modeling Nesterov’s accelerated gradient method: Theory and insights [PDF]
Su, W., Boyd, S. and Candes, E., 2014. Advances in Neural Information Processing Systems, pp. 2510—2518. - The Zen of Gradient Descent [HTML]
Hardt, M., 2013. - A geometric alternative to Nesterov’s accelerated gradient descent [PDF]
Bubeck, S., Lee, Y.T. and Singh, M., 2015. arXiv preprint arXiv:1506.08187. - An optimal first order method based on optimal quadratic averaging [PDF]
Drusvyatskiy, D., Fazel, M. and Roy, S., 2016. arXiv preprint arXiv:1604.06543. - Linear coupling: An ultimate unification of gradient and mirror descent [PDF]
Allen-Zhu, Z. and Orecchia, L., 2014. arXiv preprint arXiv:1407.1537. - Accelerating the cubic regularization of Newton’s method on convex problems [PDF]
Nesterov, Y., 2008. Mathematical Programming, Vol 112(1), pp. 159—181. Springer. DOI: 10.1007/s10107-006-0089-x
Updates and Corrections
View all changes to this article since it was first published. If you see a mistake or want to suggest a change, please create an issue on GitHub.
Citations and Reuse
Diagrams and text are licensed under Creative Commons Attribution CC-BY 2.0, unless noted otherwise, with the source available on GitHub. The figures that have been reused from other sources don’t fall under this license and can be recognized by a note in their caption: “Figure from …”.
For attribution in academic contexts, please cite this work as
Goh, "Why Momentum Really Works", Distill, 2017. http://doi.org/10.23915/distill.00006
BibTeX citation
@article{goh2017why,
author = {Goh, Gabriel},
title = {Why Momentum Really Works},
journal = {Distill},
year = {2017},
url = {http://distill.pub/2017/momentum},
doi = {10.23915/distill.00006}
}







